通过猫图识别认识神经网的最小组成单位——神经元的内部构造及运行原理
目录
前提
为了阅读本文后能后顺利的搭建起自己的深层神经网络,你需要一些必要的理论基础,这些基础本文中将不再赘述。
首先你要对机器学习、深度学习中最最基本的概念应该有一些简单的了解,比如什么叫做监督学习?什么是特征?什么是标签?
其次,你应该有一定的python以及numpy基础,但并不需要精通,如果你没有使用过python,你可以先对python进行简单的学习
再次,你需要理解线性代数中关于矩阵的基本运算,不要因为数学基础不好而惧怕,矩阵的简单加减乘除同实数一样,稍稍复杂的就是矩阵相乘了,但理解矩阵相乘并不困难,你可以翻看一下之前的大学课本了解一下矩阵相乘即可,矩阵相乘在机器学习中是最最常用的,而逆矩阵等稍微复杂的事情暂时并不需要了解。
最后,构建你的第一个深层神经网络,在统计学方面,并不需要有太多的基础,在高数方面,你可能需要了解导数的概念,仅此而已。
补充,如果你在深度学习算法领域希望深入研究,可能你需要更好的数学基础,但参考本文搭建一个自己的深度神经网络并展开训练,仅需我上面所说的就够了。本人并不建议想入门人工智能的学习者先去学习大量的数学知识。
概述
在学习吴恩达深度学习工程师课程后,编写本篇文章,希望让更多的人工智能学习者能够更快的从零开始搭建一个深层神经网络,并理解其中的细节,本文由理论到实践,力求通俗易懂,细致入微。
首先明确我们的目标,是搭建一个深层神经网络,来识别图片中是否有猫,当然了,在你学会之后,你可以拿这个网络来尝试任意你想尝试的事情,只要你有足够的训练数据。
我们分三步走,先来认识神经元(神经网络中的最小单元)大概是什么,以及其内部构造及运行原理,然后搭建一个2层的浅层神经网络,最终完成一个可以自定义神经网络层数及每层神经元个数的深层神经网络。
1 预备知识
1.1 深度学习
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
1.2 监督学习
同机器学习一样,深度机器学习方法也有监督学习与无监督学习之分
监督学习属于神经网络的一种,训练样本包含特征x以及明确的标签y
监督学习分为:回归(regression)、分类(classification)
回归:用于预测,房价预测示例
分类:用于归类,猫图试别示例
一些应用场景:
| 特征x | 标签y | 应用领域 | 神经网络类型 |
|---|---|---|---|
| home features | price | 房地产 | standard NN |
| Ad,user info | click on ad?(0/1) | 在线广告 | standard NN |
| image | object(1..1000) | 图像分类 | CNN |
| audio | text transcript | 语音识别 | RNN |
| English | Chinese | 机器翻译 | RNN |
| Image,radar info | position of other cars | 无人驾驶 | hybrid NN |
1.3 导数与行列式
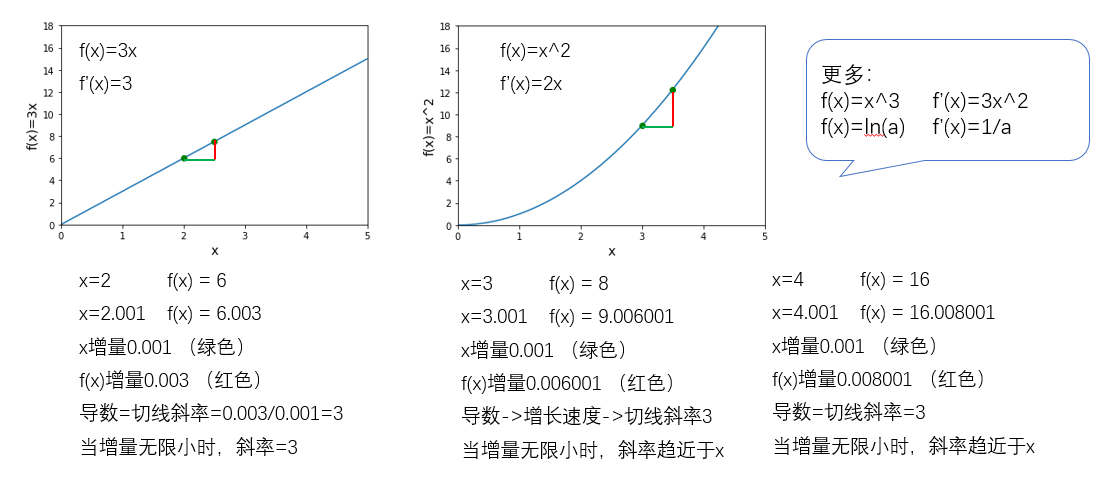
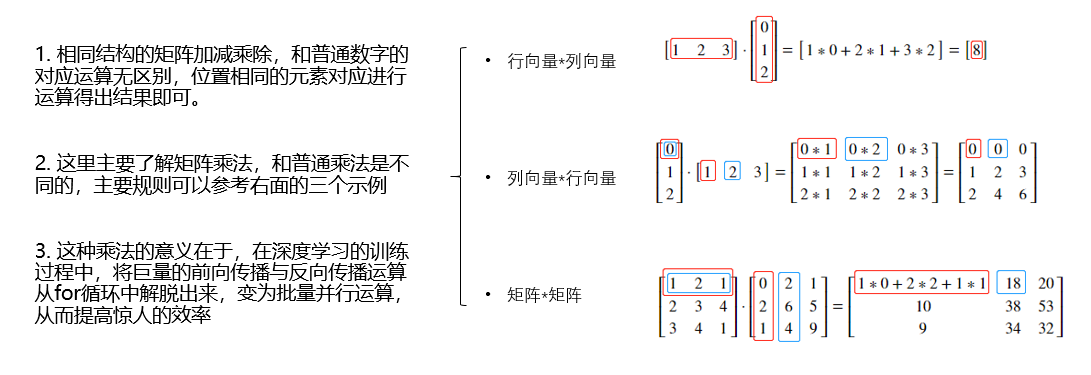
1.4 python基础
- Python基础语法:
- Python科学计算库-Numpy:
- Numpy中的秩
- 使用python的numpy时一定注意,不要使用秩为1的数组,比如如下代码此时a.shape=(5,),这样会导致不可预知的问题
a=np.random.randn(5) - 尽量用如下代码,或者使用reshape改变数组的shape
a=np.random.randn((5,1)) a=np.random.randn((1,5)) - 在编码时,可以使用assert验证数据的shape是否正常
assert(a.shape==(5,1))
- 使用python的numpy时一定注意,不要使用秩为1的数组,比如如下代码此时a.shape=(5,),这样会导致不可预知的问题
- Numpy中的广播
- 行列式的运算过程中,操作数1,操作数2,进行加减乘除时,会将操作数2进行转化,表中展示的是shape
| 操作数1 | 操作数2 | 转化后操作数2 |
|---|---|---|
| (m,n) | (1,n) | (m,n) |
| (m,n) | (m,1) | (m,n) |
| (m,1) | scalar | (m,1) |
| (1,n) | scalar | (1,n) |
2 神经网络与神经元
2.1 回归:房价预测
假设我们有一些房屋面积和售价的数据
| 面积($m^2$) | 售价(w) |
|---|---|
| 90 | 98 |
| 108 | 130 |
| 123 | 180 |
| … | … |
我们希望训练一个神经网络,能够在给出一个房屋面积的时候,预测它的售价。
在这个例子中,我们把面积看做神经网络的输入x,即为特征,把售价看做神经网络的输出y,即为标签
为了更直观,我们将数据集画到坐标系中,见图中的第一个子图,为了简便我只画出了6个点
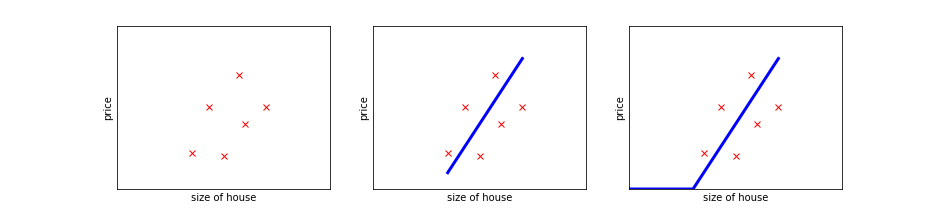
此时,可以看出,售价大概是随面积递增的,我们似乎可以找到一条直线$y=ax+b$,为了后面的叙述清晰,我们将a替换为w,这条直线变成了$y=wx+b$
w是weights的缩写叫做权重参数,可以理解为x对y的影响程度,b是bias的缩写,代表偏移量
当我们的w、b参数取值合适的时候,就得到了第二个图中的直线,神经网络的任务就是通过找到w,b更好的拟合已有的数据
通过这条直线即可达到预测的目的,但是,当x变的很小时,y可能就是负数了,我们知道y不可能为负数,所以,大致可以使用第三张图解决这个问题
我们将其抽象为一个单神经元网络(single neural network),如下图
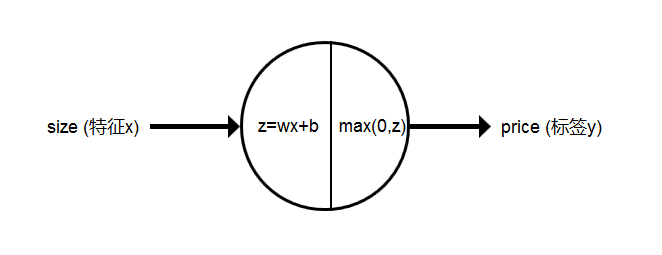
所以神经单元的任务可以分为两步,找到适合的w,b更好的拟合数据,将wx+b得到的值取非负,现在我们设置一个中间量z,那么如果我们找到了合适的w和b,神经网络的预测可以抽象为:$z = wx + b,y = max(0,z)$,这个过程可以认为就是一个神经元,神经元的后半部分,叫做激活函数,max(0,z)在机器学习中叫做ReLU激活函数(修正线性单元 Rectified Linear Unit),当然还有其他的激活函数。
实际上,影响房价的因素有很多,并不只是面积,可能如下图有四个因素能够影响售价,房屋面积和卧室数量决定了家庭数量,邮政编码决定了步行化程度,而邮政编码和财富程度决定了学校质量,最后,家庭数量、步行化程度、学校质量共同决定了售价
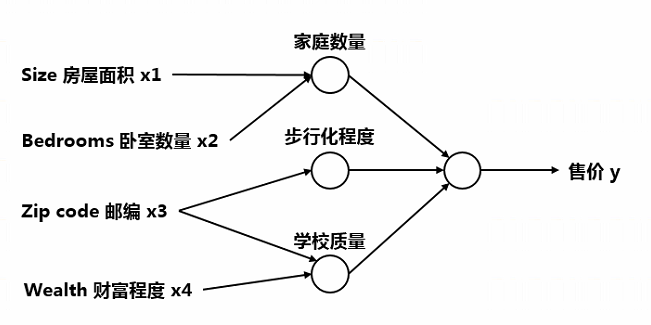
将如上情况抽象成神经网络如下
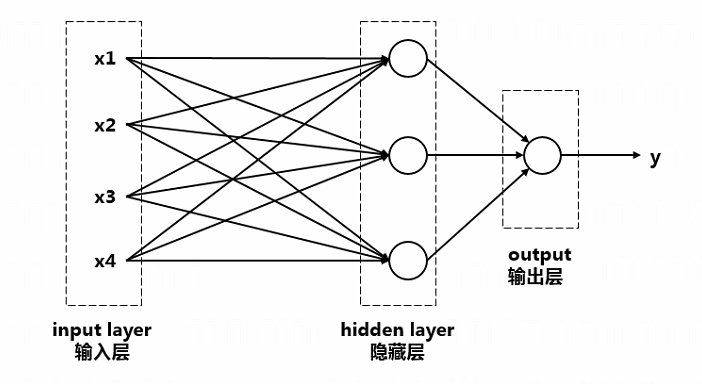
如图所示,包含输入层,隐藏层,输出层,图中的每一个圆都代表一个神经元
我们称这是一个2层神经网,输入层不算严格意义上的一层,因为其不包含神经元
隐藏层有三个神经元,拿第一个神经元来说,它并不再代表家庭数量,而是由神经网络自己决定,不对外展示意义,所以该层叫隐藏层
以隐藏层第一个神经元为例,其内部逻辑可以抽象为$z=w_1 x_1 + w_2 x_2 + w_3 x_3 + w_4x_4 + b, a=max(0,z)$,$a$表示该神经元对外的输出,也叫激活值,$w_i$表示$x_i$对该神经元影响的程度,即权重,我们对各层之间进行全连接,即每两个元素都会相连,所以第一个神经元默认是和四个输入都有关系的,而不是人为的仅仅将其与$x_1,x_2$连接,我们说过,隐层神经元的意义由神经网络自己决定,而不是人为控制,若该神经元真的与$x_3,x_4$无关,在学习的过程中,$w_3, w_4$自然会趋近于零,从而消除其关联性,这就是神经网络的神奇之处
2.2 分类:猫图识别
如何将图像转化为输入数据?分解成三个颜色通道的数字矩阵,再转化为一个向量
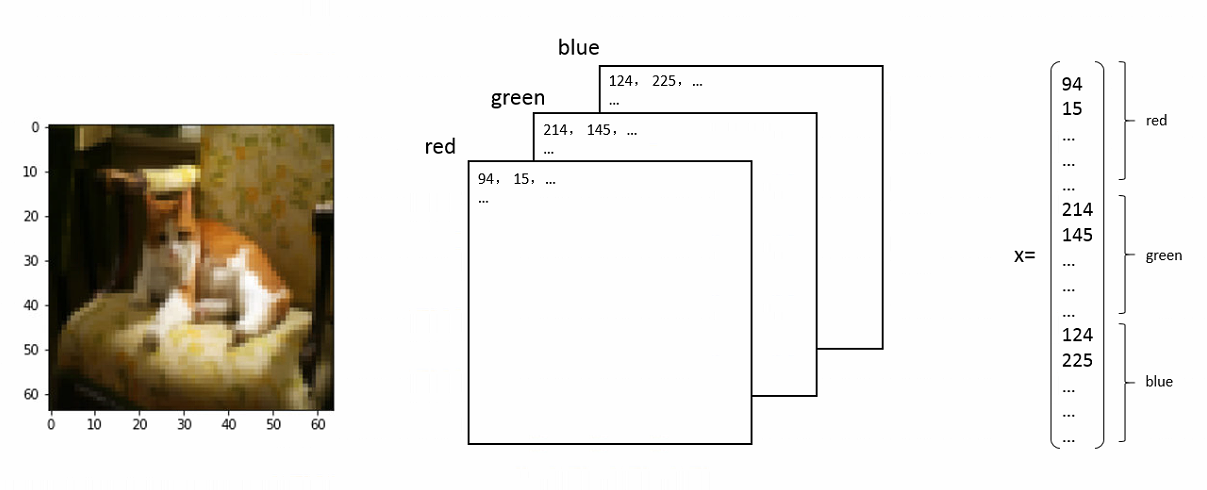
单个神经元识别图中是否有猫的整体思路
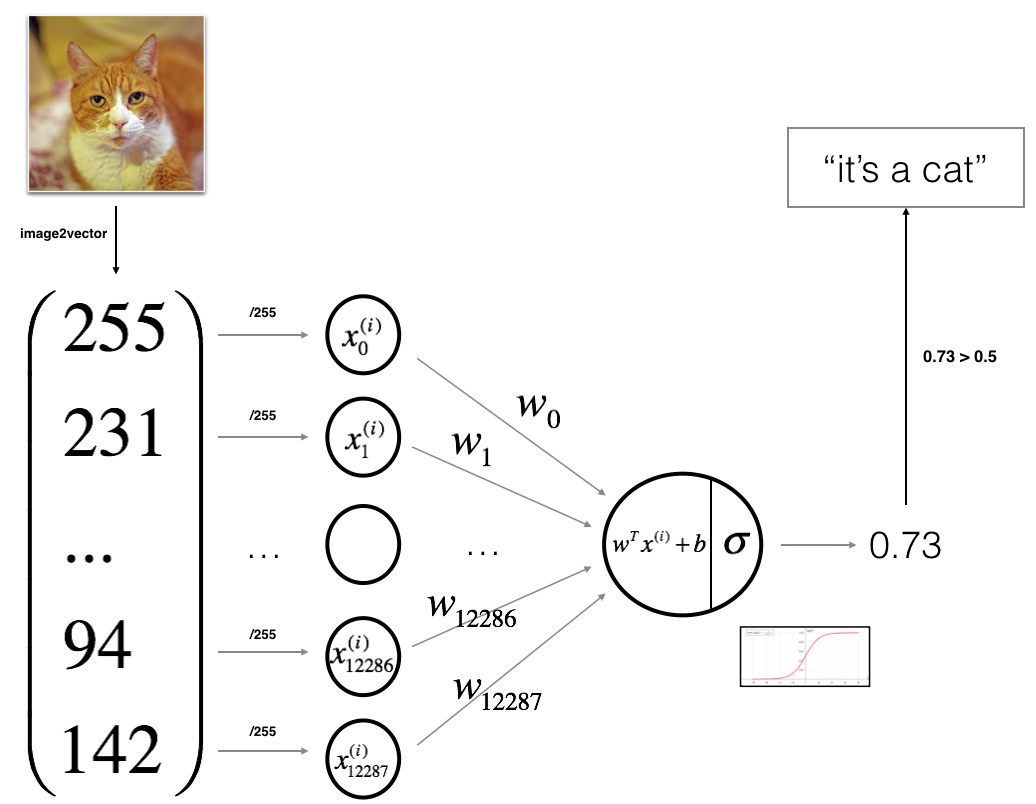
通过上面的示例引出一些常用的表示方式
$x \in \mathbb{R}^{n_x}, y \in {0, 1}$
$m$ 表示样本的数量,$m_{train},m_{test}$ 分别表示训练集、测试集的样本数量,编码时使用”m_train”,”m_test”
$x^{(i)}$ 表示第i个样本的特征, $y^{(i)}$ 表示第i个样本的标签
训练集可以表示为 ${(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),(x^{(3)},y^{(3)}),…,(x^{(m)},y^{(m)})}$
我们习惯将x,y分别放入大的矩阵中,记为
-
$X=[x^{(1)},x^{(2)},x^{(3)},…,x^{(m)}]$ , X.shape=$(n_x,m)$
-
$Y=[y^{(1)},y^{(2)},y^{(3)},…,y^{(m)}]$ , Y.shape=$(1,m)$
3 逻辑回归
3.1 sigmoid激活函数
监督学习的一种,我们希望 $y=0/1$ 或 $y\in[0,1]$ 时使用
以识别图中是否有猫为例,我们输入x,并希望得到$\hat{y}=P(y=1\mid x)$ , $\hat{y}$表示有猫的概率
逻辑回归中涉及到了如下参数:
- 输入: $x\in\mathbb{R}^{n_x}$
- 输出: $\hat{y}\in[0,1], \hat{y}=\sigma(w^T x + b)$ 表示图中有猫的概率
- 权重: $w\in\mathbb{R}^{n_x}$
- 偏移量: $b\in\mathbb{R}$
- 标签: $y\in 0,1$
sigmoid,公式:$s=\sigma(z)=\frac{1}{1+e^{-z}}$, 图像如下
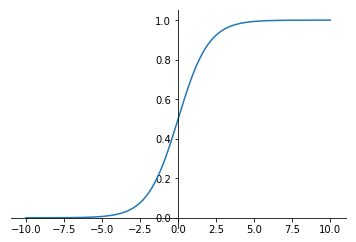
$z=w^T x + b $, 这一步计算是线性的,而我们希望输出在 $[0,1]$ 区间内,使用sigmoid激活函数
当 $z$ 很大时,$\sigma(z)$ 趋近于1
当 $z$ 很小时,$\sigma(z)$ 趋近于0
3.2 逻辑回归中的成本函数
在逻辑回归中,我们得到样本 $(x^{(i)},y^{(i)})$ ,希望 $\hat{y}^{(i)}\approx y^{(i)}$
损失函数/误差函数(loss function/error function)
用于计算某一样本的误差,$L(\hat{y}^{(i)},y^{(i)})=\frac{1}{2}(\hat{y}^{(i)}-y^{(i)})^2$ 是计算误差的一个很好的方式,但是在优化过程中会导致函数非凸,梯度下降不能达到效果,所以在逻辑回归中,我们使用下面的公式
我们不需要纠结怎么得出的这个公式,我们看看公式效果
- 当 $y^{(i)}=1$ 时,$L=-log(\hat{y}^{(i)})$ ,若损失L减小, 则$log(\hat{y}^{(i)})$ 增大, 则$\hat{y}^{(i)}$增大,越大越趋近于1
- 当 $y^{(i)}=0$ 时,$L=-log(1-\hat{y}^{(i)})$ ,若损失L减小, 则$log(1-\hat{y}^{(i)})$ 增大, 则$1-\hat{y}^{(i)}$增大,则$\hat{y}^{(i)}$减小,越小越趋近于0
我们只要降低L,就能达到 $\hat{y}^{(i)}\approx y^{(i)}$ 的目的
其实,又很多形式的公式能够达到这个效果,选用这个公式作为损失函数公式的原因,是该函数为凸函数,利于进行梯度下降优化。如果函数非凸,梯度下降有可能下降到局部最优解,影响优化过程
成本函数(cost function)
用于衡量在全体训练集上的表现,用每个样本的损失和的均值表示
3.3 梯度下降
回顾逻辑回归的例子
$\hat{y}=\sigma(w^T x+b)$
$\sigma(z)=\frac{1}{1+e^{-z}}$
$J(w,b)=\frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}log(\hat{y}^{(i)})+(1-y^{(i)})log(1-\hat{y}^{(i)})]$
我们的目的是找到合适的w、b,使J最小,如果w是一个标量,即只有一个特征,可以得到如下的图像
为了直观,我们先忽略b
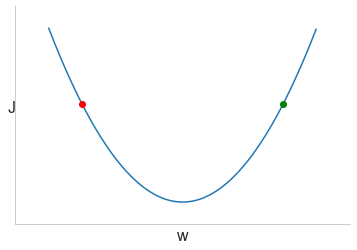
梯度下降的过程就是重复 $w=w-\alpha\frac{dJ(w)}{dw}$ ,其中 $\alpha$ 表示学习率,$\alpha$ 越大,梯度下降越快
$\frac{dJ(w)}{dw}$ 为曲线的斜率,在w点的导数,编码时用”dw”表示
若起点在红点处,$dw<0$ 经过 $w=w-\alpha\frac{dJ(w)}{dw}$,w将增大,向右一步走
若起点在绿点处,$dw>0$ 经过 $w=w-\alpha\frac{dJ(w)}{dw}$,w将减小,向左一步走
重复梯度下降的过程可以使最后得到的w对应点趋近于曲线的最低点,而最低点处J最小
针对于原函数 $J(w,b)$ ,梯度下降实际上是重复如下过程
参数超过一个时,使用 $\partial$ 代替 $d$ ,$\partial$ 表示偏导数,编码时用”dw”,”db”表示
3.4 计算图
神经网络的计算过程:
- 计算神经网络输出(前向传播)
- 计算对应的梯度(反向传播)
从一个简单的例子认识计算图,设: $J(a,b,c)=3(a+bc)$
使用中间变量将计算过程拆解: $u=bc$ , $v=a+u$ , $J=3v$
设 $a=5$ , $b=3$ , $c=2$ ,先正向计算依次计算中间值和最终值,然后按虚线方向计算梯度
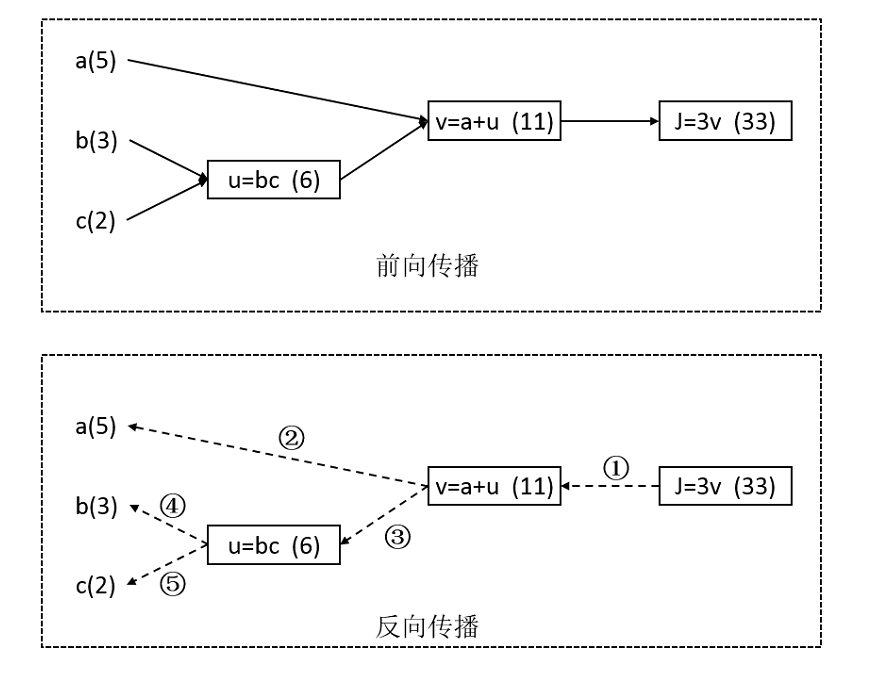
反向传播详细步骤如下:
- ① 求v的梯度,$\frac{dJ}{dv}=3$ 理解为v增长1,J增长3
- ② 求a的梯度,$\frac{dJ}{da}=\frac{dv}{da}·\frac{dJ}{dv}=1·3=3$ 理解为a增长1,J增长3
- ③ 求u的梯度,$\frac{dJ}{du}=\frac{dv}{du}·\frac{dJ}{dv}=1·3=3$ 理解为u增长1,J增长3
- ④ 求b的梯度,$\frac{dJ}{db}=\frac{du}{db}·\frac{dJ}{du}=2·3=6$ 理解为b增长1,J增长6
- ⑤ 求c的梯度,$\frac{dJ}{dc}=\frac{du}{dc}·\frac{dJ}{du}=3·3=9$ 理解为c增长1,J增长9
3.5 逻辑回归中的梯度下降
回顾相关公式
$\hat{y}=a=\sigma(w^T x+b)$,$\sigma(z)=\frac{1}{1+e^{-z}}$,$z=w^T x+b$
单个样本损失函数 $L(a,y)=-[ylog(a)+(1-y)log(1-a)]$
全部样本成本函数 $J(w,b)=-\frac{1}{m}\sum_{i=1}^mL(a^{(i)},y^{(i)})$
单个样本的反向传播过程
假设有两个特征值x1,x2,先通过正向传播计算出L值,并记录计算过程中的z,a的值用于反向传播
正向传播过程图略,反向传播过程如下
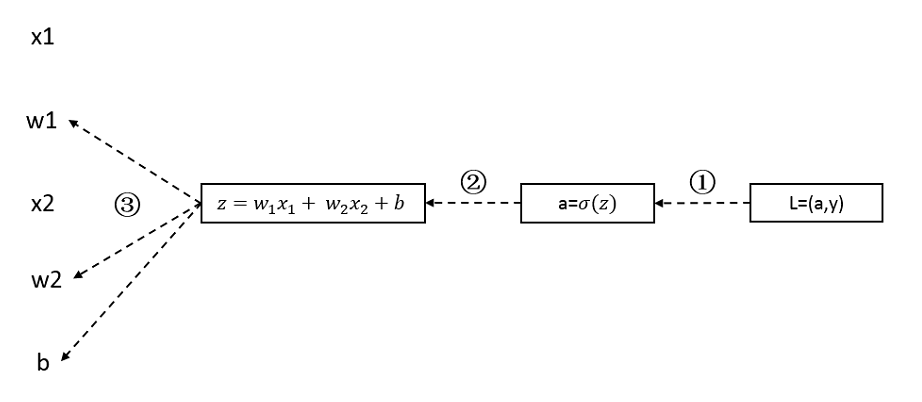
我们的目标是不断更新 $w_1,w_2,b$,从而使L变小,我们先要通过反向传播计算出”dw1”,”dw2”,”db”
- ① “da” = $\frac{L}{da}=-\frac{y}{a}+\frac{1-y}{1-a}$
- ② “dz” = $\frac{dL}{dz}=-\frac{dL}{da}·\frac{da}{dz}=(-\frac{y}{a}+\frac{1-y}{1-a})·[a(1-a)]=a-y$
- ③ “db” = “dz”, “dw1” = x1“dz”, “dw2” = x2“dz”
通过反向传播我们得到了梯度值:
- dw1 = x1(a-y)
- dw2 = x2(a-y)
- db = a-y
然后我们可以进行梯度下降
- $w1 = w1 - \alpha dw1$
- $w2 = w2 - \alpha dw2$
- $b = b - \alpha db$
m个样本的反向传播过程
之前讨论的针对某一样本 $(x^{(i)},y^{(i)})$,求出 $dw_{1}^{(i)},dw_{2}^{(i)},db$
在m个样本中,以 $dw_1$ 为例,实际上是所有样本的 $dw_{1}^{(i)}$ 的均值
写一个算法示例(仅为了表述过程,不能执行),实现m个样本的一次梯度下降
J = 0, dw1 = 0,dw2 = 0, db=0
for i=1 to m:
#正向传播
zi = w.T * xi + b
#这里的w是包含w1,w2的向量
# xi表示第i个样本的两个特征组成的向量
ai = sigmoid(zi)
J += -[yi * log(ai)+(1-yi)log(1-ai)]
#反向传播
dzi = ai - yi
dw1 += xi[0]dzi
dw2 += xi[1]dzi # 当n= n_x时,这里也是一个for loop
db += dzi
J /= m, dw1 /= m, dw2 /= m, db /= m #计算均值
#梯度下降
w1 -= learning_rate * dw1
w2 -= learning_rate * dw2
b -= learning_rate * db
可以看出,一次梯度下降过程中,需要使用两次显示for loop,第一次,循环m个样本,第二次,循环n_x个特征
显示调用for loop会使计算效率很低,后面我们将会用向量化来消除这两个for loop
3.6 向量化
使用矩阵运算代替for
如,当我们计算 $z=w^T x+b$ 时,$w,x\in\mathbb{R}^{n_x}$
for循环是这样计算的
z = 0
for i in range(n_x)
z += w[i]* x[i]
z += b
向量化后
z = np.dot(w.T, x)
在使用np.function时,充分利用CPU/GPU并行化计算,SIMD计算,大大提高计算速度
来看个小例子对比两种计算的区别
import numpy as np
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a,b)
toc = time.time()
print("vectorization:", str(1000*(toc-tic)),'ms, value:',c)
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print("for loop:", str(1000*(toc-tic)),'ms, value:',c)
vectorization: 4.000425338745117 ms, value: 249913.1073508986
for loop: 503.02863121032715 ms, value: 249913.10735088808
之前的例子是两个向量相乘,同样的方式,可以计算矩阵和向量相乘,矩阵相乘
另外np.exp()可以将矩阵的每个元素求指数,类似的还有
- np.log(v)
- np.abs(v)
- np.maximum(v)
- v ** 2
- 1/v
3.7 向量化实现逻辑回归前向传播
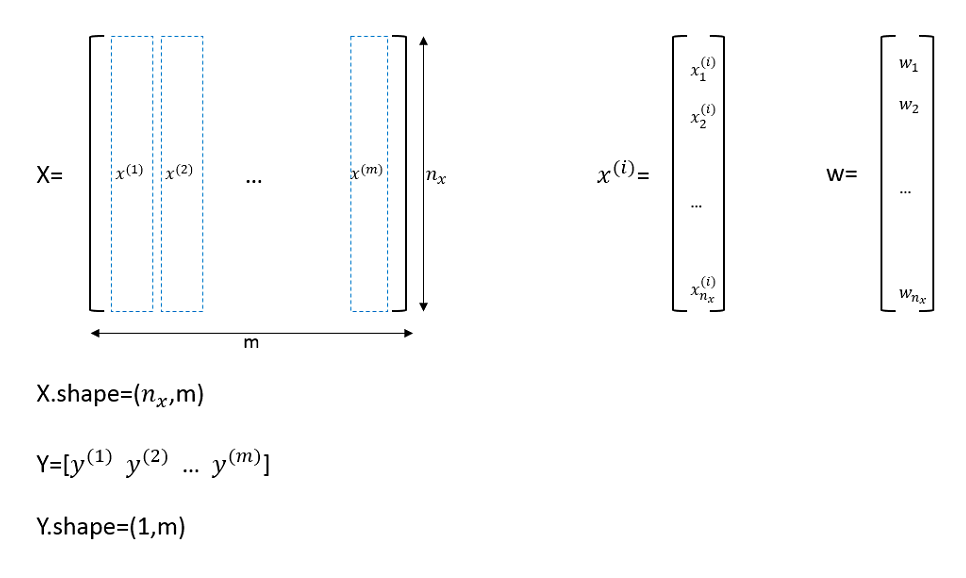
在讨论二分类时,我们将所有的x,y分别放入了一个矩阵中
下图中展示了矩阵X、Y、以及第i一个样本向量$x^{(i)}$、参数w,另外参数b是一个标量,不做展示
未使用向量化时,正向传播过程如下
$z^{(1)}=w^T x^{(1)}+b , a^{(1)}=\sigma(z^{(1)})$
$z^{(2)}=w^T x^{(2)}+b , a^{(2)}=\sigma(z^{(2)})$
…
$z^{(m)}=w^T x^{(m)}+b , a^{(m)}=\sigma(z^{(m)})$
我们将所有的 $a^{(i)}、z^{(i)}$分别放入矩阵Z、A中,得到
$A=[a^{(1)},a^{(2)} , … ,a^{(m)}]=\sigma(Z)=[\sigma(z^{(1)}),\sigma(z^{(2)}),…,\sigma(z^{(m)})]$
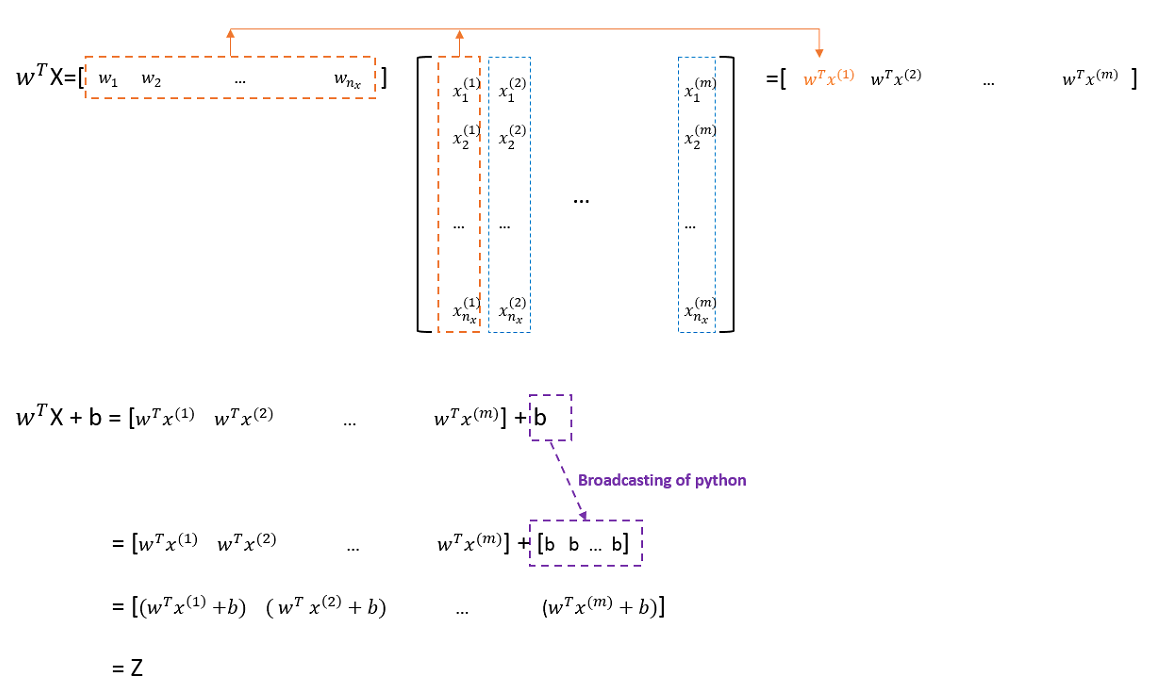
$Z=[z^{(1)},z^{(2)},…,z^{(m)}]=w^T X + b=[(w^T x^{(1)}+b),(w^T x^{(2)}+b),…,(w^T x^{(m)}+b) ]$
计算过程$w^T X + b$细化如下图
3.8 向量化实现逻辑回归反向传播
回顾一下反向传播计算过程
首先,通过前向传播,我们得到了 $A=[a^{(1)},a^{(2)},…,a^{(m)}]$ , 标签 $Y=[y^{(1)},y^{(2)},…,y^{(m)}]$
这时,我们可以计算出所有样本的 $dz^{(i)}$ 并放入一个矩阵dZ中
$dZ=[dz^{(1)},dz^{(2)},…,dz^{(m)}]=[(a^{(1)}-y^{(1)}),(a^{(2)}-y^{(2)}),…,(a^{(m)}-y^{(m)})]=A-Y$
推到出dZ的计算公式:dZ = A - Y
$db=[db^{(1)},db^{(2)},…,db^{(m)}]=[dz^{(1)},dz^{(2)},…,dz^{(m)}]=\frac{1}{m}\sum_{i=1}^mdz^{(i)}=\frac{1}{m}np.sum(dZ)$
推到出db的计算公式:db = 1/m * np.sum(dZ)
针对于特征的权重 $w_1,w_2,…,w_{n_x}$ 的梯度
$dw_1=[(dx_1^{(1)}* dz^{(1)}),(dx_1^{(2)}* dz^{(2)}),…,(dx_1^{(m)}* dz^{(m)})]$
$dw_2=[(dx_2^{(1)}* dz^{(1)}),(dx_2^{(2)}* dz^{(2)}),…,(dx_2^{(m)}* dz^{(m)})]$
…
$dw_{n_x}=[(dx_{n_x}^{(1)}* dz^{(1)}),(dx_{n_x}^{(2)}* dz^{(2)}),…,(dx_{nx}^{(m)}* dz^{(m)})]$
一次性计算所有特征 $dw$ 如下图
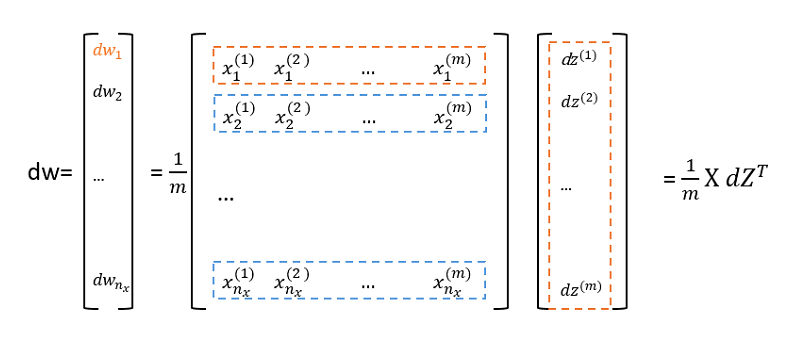
推到出dw的计算公式:dw = 1/m * np.dot(X,dZ.T)
这也就消除了之前所提到的两个for loop,可以将一次梯度下降的算法代码整理如下
#前向传播
Z = np.dot(w.T,X) + b
A = sigmoid(Z)
#反向传播
dZ = A - Y
dw = 1/m * np.dot(X, dZ.T)
db = 1/m * np.sum(dZ)
#梯度下降
w -= learning_rate * dw
b -= learning_rate * db
这只是一次梯度下降过程,如果需要迭代多次,将不可避免的使用显示的 for loop

